









Optimized and secured computer systems are vital to keep your business moving. When it comes to IT and cybersecurity, we’re dedicated to providing the best to our clients. Discover how we can position your company for profitability and success. Read More
RIGHT FIT MEETING


ASSESSMENT
DISCOVERY & ONBOARDING


IMPLEMENTATION
SERVICE DELIVERY & QUARTERLY BUSINESS REVIEWS

Swift Chip provides managed IT and cybersecurity services for a wide variety of companies in fields with stringent privacy and compliance requirements. Read More
FINANCIAL SERVICES
LEGAL
MANUFACTURING
MEDICAL
NON PROFIT
TECHNOLOGY
Ransomware threats, cyberattacks, and data breaches can cripple your business. Understand your options for preventing major losses and lawsuits.
Reliable IT is a crucial resource for a small- to medium-sized business, but one you can rarely afford to focus…
Read MoreThe single biggest risk to your company’s cybersecurity is human error. When your users naively give malicious actors access to…
Read MoreWith cyber threats increasing in both number and sophistication, threat hunting is an essential component of any business’ cybersecurity strategy.…
Read MoreEffective cybersecurity is not a static state. Computer systems, applications, and network infrastructure are constantly changing with upgrades and updates,…
Read MoreThe worst way to find out that your cybersecurity isn’t doing its job is when a hacker successfully breaks into…
Read MoreFrom eMail security to network challenges in the office, save time and hassle when you outsource your IT support with our team of dedicated IT professionals.
Moving your business forward means having IT infrastructure that can keep up with growing demands. For small- to medium-sized enterprises, sparing the time from the pressing day-to-day needs of running…
Read MoreAchieve workplace modernization on a budget with Swift Chip’s Cloud Services. Our future-oriented solutions allow your organization to be sustainable, efficient, and competitive with freedom to scale resources as your…
Read MoreGetting the most out of your technology means making sure that you and your staff are comfortable and proficient with your systems and software. Swift Chip can help existing employees…
Read More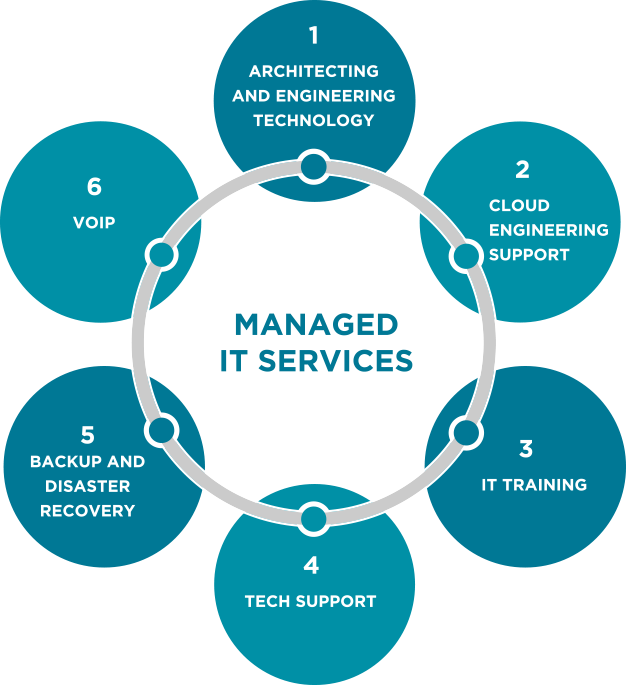
We’ve partnered with Swift Chip for nearly 11 years and our partnership continues to progress and be reliable. Our IT needs are always met, Swift Chip is always there in the event we need them. Thank you Swift Chip!![]()
As I am not tech savvy, I call SwiftChip for every little issue I have, but they respond quickly and provide the superior service I have never received from any other vendors. Love working with all its technicians. Thank you for making my life so much easier, the Swiftchip team.![]()
Very professional and quick response. We count on our IT firm to keep our clients safe. This is the firm to hire for peace of mind. We can always get a knowledgeable professional to assist our team.![]()
Swift Chip has been our IT Consultant for the past four years and have helped us clean up our technology mess! Swift Chip technician’s are easy to work with, courteous and timely. If an issue ever arises, they are there to help same day and they work diligently to figure out the issue if its not an easy fix. They are the perfect fit for our IT needs!
News, tips, and insights on issues related to IT, cybersecurity, emerging online threats, and more.



Did you know that cyber crime is predicted to cost the world $10.5 trillion annually by 2025? Don't let your business become a statistic! Utilize the knowledge and practical strategies presented in our Cyber Security Essentials booklet to navigate the ever-evolving digital landscape with greater confidence and peace of mind. Fortify your business against cyber threats—download your copy now and invest in a more secure future!
Uncover a unique fusion of ancient wisdom and modern cybersecurity in 'The Art of Hacking: Ancient Wisdom for Cybersecurity Defense' by Swift Chip's very own Certified Ethical Hacker, Ken May. Through thought-provoking questions like 'If Sun Tzu hacked you, how would you be able to stop him?' and 'What did the Samurai know about firewalls?', Ken reveals powerful insights and practical techniques for defending against today’s cyber threats. Equip yourself with a fresh, strategic approach to cybersecurity by downloading this one-of-a-kind book!
Swift Chip provides managed IT and cybersecurity services for a wide variety of companies in fields with stringent privacy and compliance requirements.